2024-09-26 16:23:47.AIbase.12.0k
Jointly Developed by Zhejiang University and Tsinghua University! Voice Forgery Detection Framework SafeEar Achieves an Error Rate as Low as 2.02%
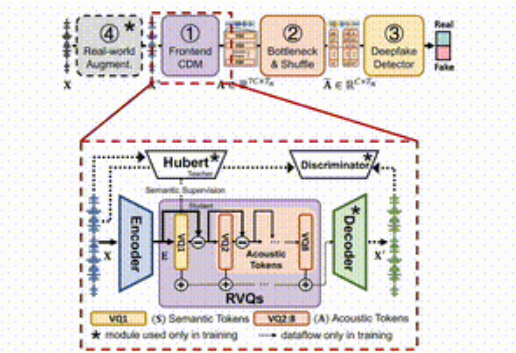
In the context of rapid advancements in voice synthesis technology, voice forgery has become increasingly severe, posing significant threats to user privacy and social security. Recently, the Intelligent System Security Laboratory at Zhejiang University and Tsinghua University jointly released a novel voice forgery detection framework called 'SafeEar.' This framework aims to efficiently detect forgeries while protecting the privacy of voice content. The concept behind SafeEar is to cleverly design a decoupled model based on neural audio codecs that effectively separates the acoustic features of voice.